
Why CSAT May Not Help to Measure the Quality of Your Support
Each business specialty has its quality metrics. For sales managers, it’s the number of closed deals. For content managers, it’s the number of clicks, likes, and comments. For marketers, it’s the number of new clients. And for the support, it is – traditionally – the number of satisfied customers.
Quite a lot rides on these metrics. They are used to evaluate the effectiveness of the chosen strategies, measure professional performance, and indicate the career prospects of the specialist. Often they directly influence monthly wages.
If so, there has to be a clear understanding of how these metrics work, whether they measure exactly what you want to measure, and whether the results are objective and conclusive.
Let’s take, for example, the number of satisfied customers. The numeral part of the metric is clear. However, how precisely can we measure and describe satisfaction? How precise can we be when measuring something related to emotions?
Naturally, there is a metric that – in theory – should help us estimate the strength of our customers’ love. It is called Customer Satisfaction Score, or CSAT for short. You get the data for calculations using a short customer survey, in which your customers need to rate their communication with the company. It would seem the procedure is quite simple and suggests a straightforward result. However, a deeper analysis confirms our initial suspicions – a personal impression cannot always be presented adequately via a metric system.
In this article, we will try to find out if CSAT is well-suited for customer service evaluation, for game support in particular. We shall analyze the factors that influence the users’ opinion and the reasons that make them give a certain number of stars to support. We will try to understand what lies behind dry figures and how much we can really trust those.
Some necessary terms
Before we dive into our analysis, let us refresh our memory and look at some terms related to metrics.
CSAT = Customer Satisfaction Score shows how much your customer is satisfied with your product, your services, or their communication with your brand. It is used, as a rule, to rate a certain communication point (for example, a chat with a customer support agent) and not the perception of the brand as a whole. It is usually measured via a scale from 1 to 5:

Аnd sometimes from 1 to 10 or from 1 to 3:

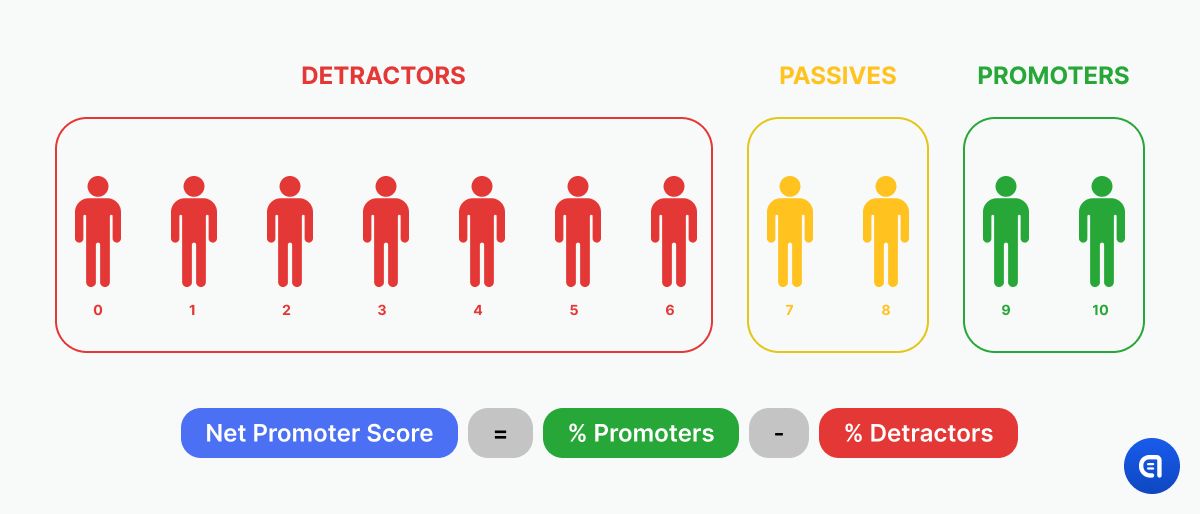
NPS = Net Promoter Score shows how likely it is that a customer will recommend your company or product to their friends and family. It is measured on a scale from 1 to 10:

Those customers who are ready to recommend you to others are called promoters. Those who are not quite sure are called passives. And those who openly decline to promote you are considered detractors. NPS is used to estimate the overall loyalty to the brand.
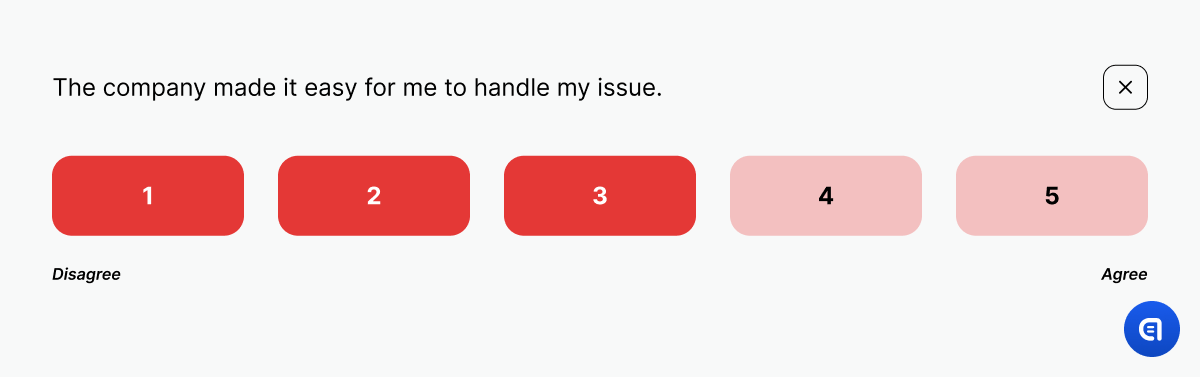
CES = Customer Effort Score tells us how easy it is for your customers to communicate with the company; how much effort it requires for them, say, to receive some goods or to solve a problem.
Read more: Why it is Crucial to Train your Agents
CSAT – so easy to grasp and so available
CSAT is one of the most popular metrics for evaluating the quality of customer service. The secret of its success is simple: CSAT is easy to measure, and its result is easy to present.
Numerous customer service helpdesks put CSAT as an in-built feature directly into the chat between an agent and a user. It is convenient: companies do not have to pay extra, and users are encouraged to share their opinion. They only need to tap on the number of stars and leave a more detailed commentary if they so wish. The fewer actions customers need to take, the bigger the possibility that they will rate the conversation and the more feedback the company will receive. As a result, the more feedback the company gets, the more they can improve the quality of their service.
On the flip side, the popularity and usability of CSAT often make it the only metric that a company relies on when measuring the quality of support service.
From the outside, everything looks simple enough: the user has a chat with support and then rates the service. However, if we look inside the mechanism, analyze dialogues, and study user commentaries, then the intricacies of the whole process become apparent.
Method of analysis
Let us try to understand why this simple and popular way or evaluation may fail in its task.To get the data we need, we will analyze the CSAT of two Ansvery support teams. Each of these teams works with a single client. Team 1 (T1) supports one mid-core game, and Team 2 (T2) – two casual games. Both clients have chosen the same helpdesk (Helpshift) where users can rate each dialogue with the support and explain their choice in a commentary.
At first, we shall take all the tickets for 1, 3, and 6 months and divide them into groups according to the rating. Thus we can see if any consistent patterns emerge. Then we will analyze commentaries inside each group and divide them into categories according to the reasons that made users give the conversation this particular number of stars. The percentage of these commentaries will be later shown in tables.
Level 1 – number and proportion of ratings; percentage of ratings with commentaries and informative value of the latter
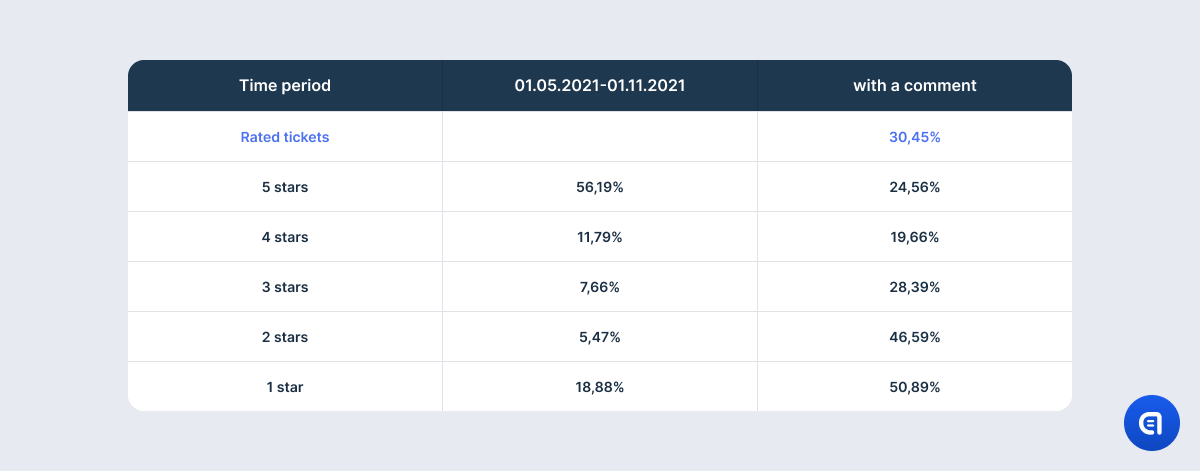
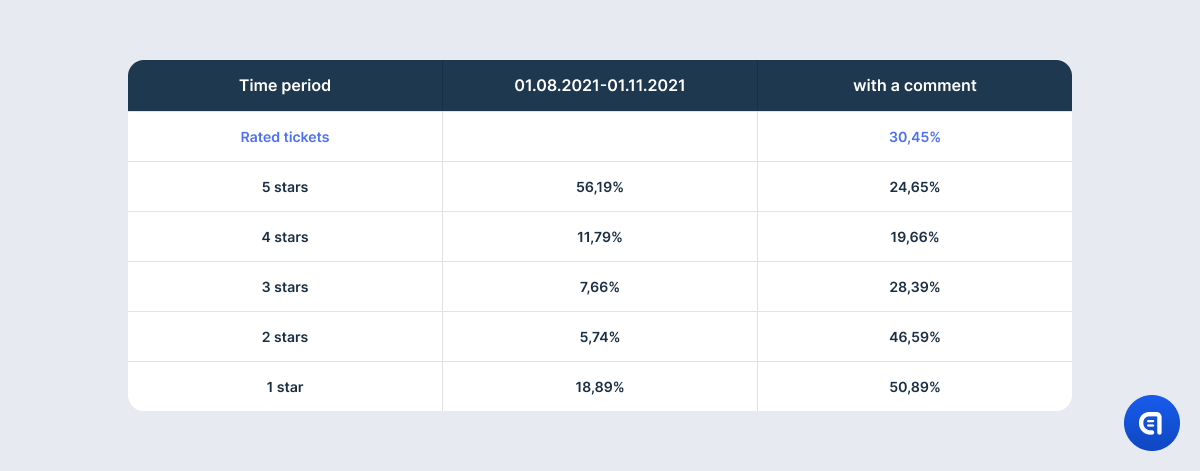
The proportion of tickets with ratings during six months confirms an old truth that users tend to go extreme. The most popular ratings are 5 and 1. It is much simpler to give the maximum or the minimum number of stars than to decide how many stars to take off and why. Also, extreme emotions, both positive and negative, are the strongest motivators to rate your experience.
At the same time, anger or irritation are the mightiest reasons to express your opinion in words. This is why, though 5 is the most common rating (56%), only 24,5% of the happy users left a comment. Because if everything is great, why talk about it? At the same time, 51% of one-star ratings (19% of the total number of tickets with rating) was accompanied by a comment.
6 months:
3 months:
1 month:
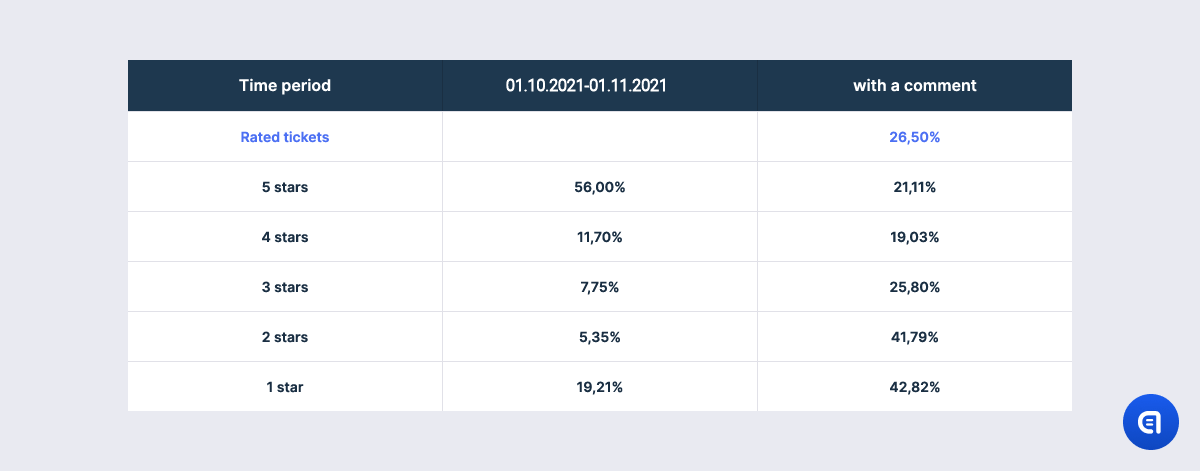
Starting with the 4-star rating, there is an inverse relationship between the number of stars and the comments. The lower the rating, the more often it is accompanied by user feedback.
The information one can get from the comment is also connected to the users’ emotions. For example, a 5-star rating is usually accompanied by remarks like “great”, “awesome”, etc., with no further explanation.
Comments to 4-star ratings are scarce, and those that do reach us are usually brief. Dissatisfaction in such cases may be so insignificant that it does not inspire wordy feedback.
The most detailed feedback, it seems, comes with 3-star ratings. In these comments, users usually explain at length why they’ve taken away two stars and what the company should improve.
Two-star ratings are the fewest, which is understandable – when you are really displeased, you’ll simply tap on one star. 1- and 2-star rating comments are similar in the amount of information they provide. Sometimes we can find one-word feedback, and sometimes – long paragraphs of text full of vibrant negative emotions.
Level 2 – singling out characteristics
As was mentioned before, five-star rating comments do not often contain any explanations. However, sometimes users provide more detailed descriptions that allow us to understand what moves them to give their experience the highest rating and what characteristics make quality support.
Negative comments help us discover what upsets users the most and what issues in their communication with the company make them lower their rating.
To tell you the truth, we would hope that we would be able to see some pattern in which issues cost the company just one star, which ones deprive them of two, and which ones cannot be forgiven at all and prompt a 1-star rating. However, this did not happen. It turned out that users can name the same reasons regardless of whether they give a 4-star or 1-star rating. For example, they had to wait for too long. Or they received a reply that the issue is still being handled and they will get a fix only in the next update. So even at this level, we receive an indication that CSAT is not a completely reliable metric. It is not that some users had to wait longer or one issue was more serious than the other. Reaction to the same problems and the same wait time can be absolutely different.
So, firstly, the rating may depend on the user’s character. Some customers are calmer by nature and seldom lose their cool, while others may believe that aggression is a great negotiation tool. Secondly, we need to remember that we are talking about game support here, and games can cause quite a lot of anger and frustration. For example, if a user plays a mid-core game, they can face a bug in the middle of a session when their adrenaline level is high. When such a session is interrupted suddenly, this can cause anger which, in turn, will greatly influence the tone of the conversation with the support. And support may do everything in their power and apply all the known communication techniques, but the user will still want to vent and share their frustration with the company.
Level 3 - evaluation criteria, the contents of the remarks, intermixing of the metrics
The idea is that if CSAT indicates the quality of customer service, then specific remarks in user feedback should help us create a list of characteristics that make up good or bad support. However, in practice, the points that users bring up do not correspond only with the dialogue with a support agent but with the whole interaction with the game or the brand.
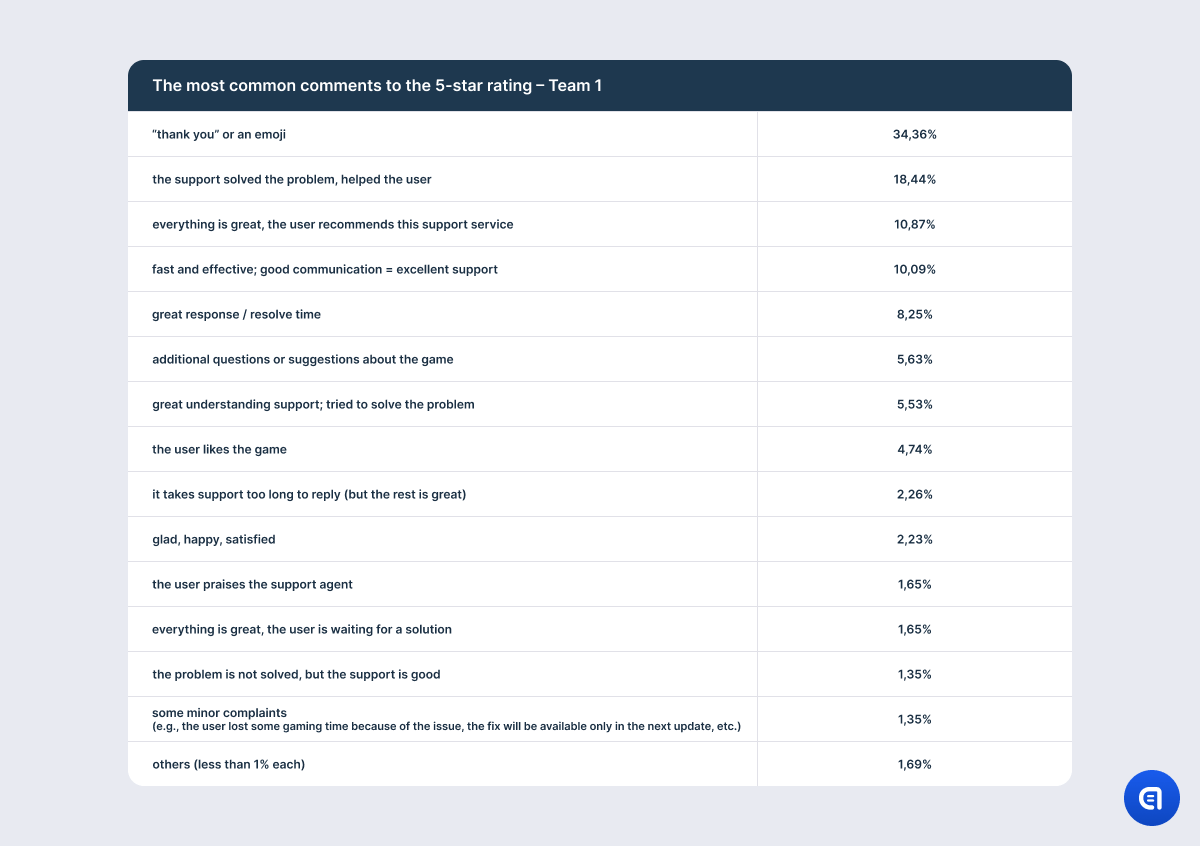
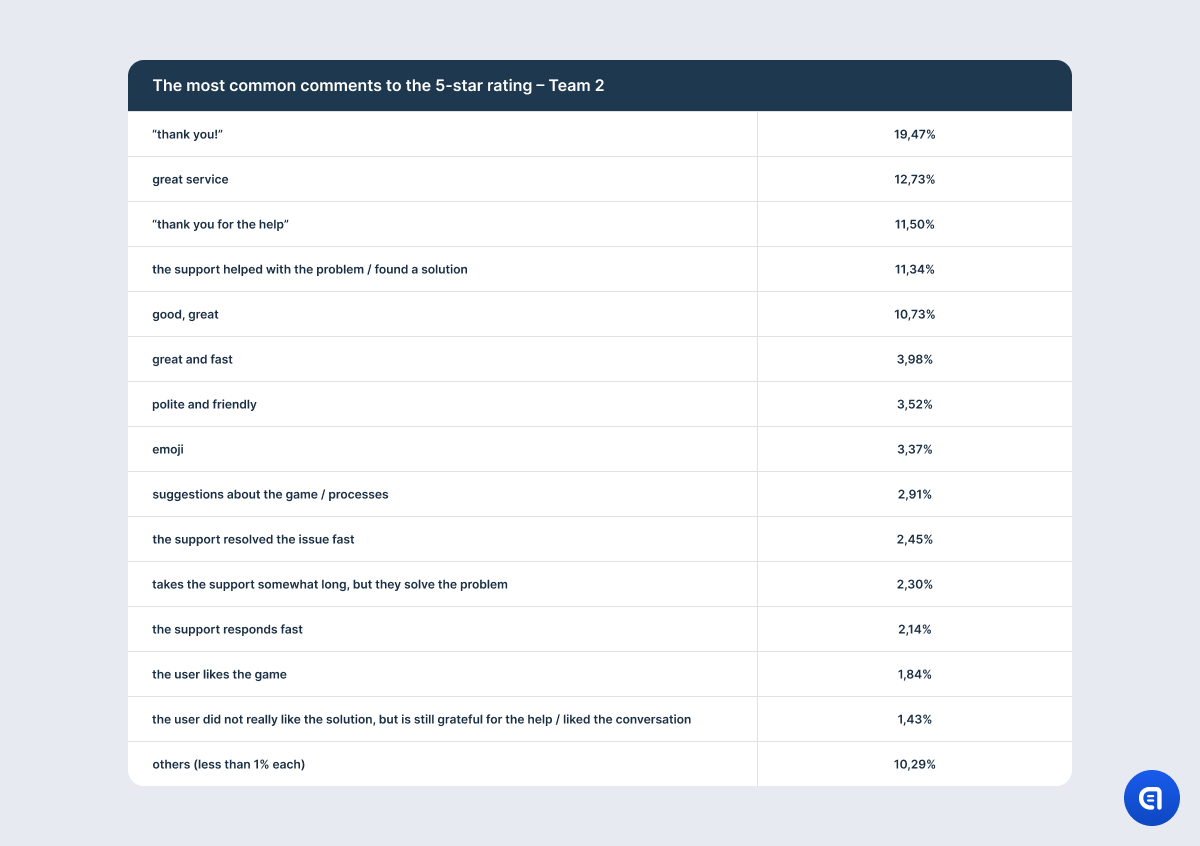
We can see it even in the comments to 5-star ratings, although positive feedback is the closest to the ideal CSAT model that companies want. For example, users mention pleasant conversation, understanding and empathy, effective communication, attention to detail, and all of these remarks are definitely related to their chat with support. Some users even specifically underline the quality of communication since their issue is not yet resolved. However, there are users who praise the game and the dev team and share their ideas and recommendations on gameplay that are not connected to the initial request.
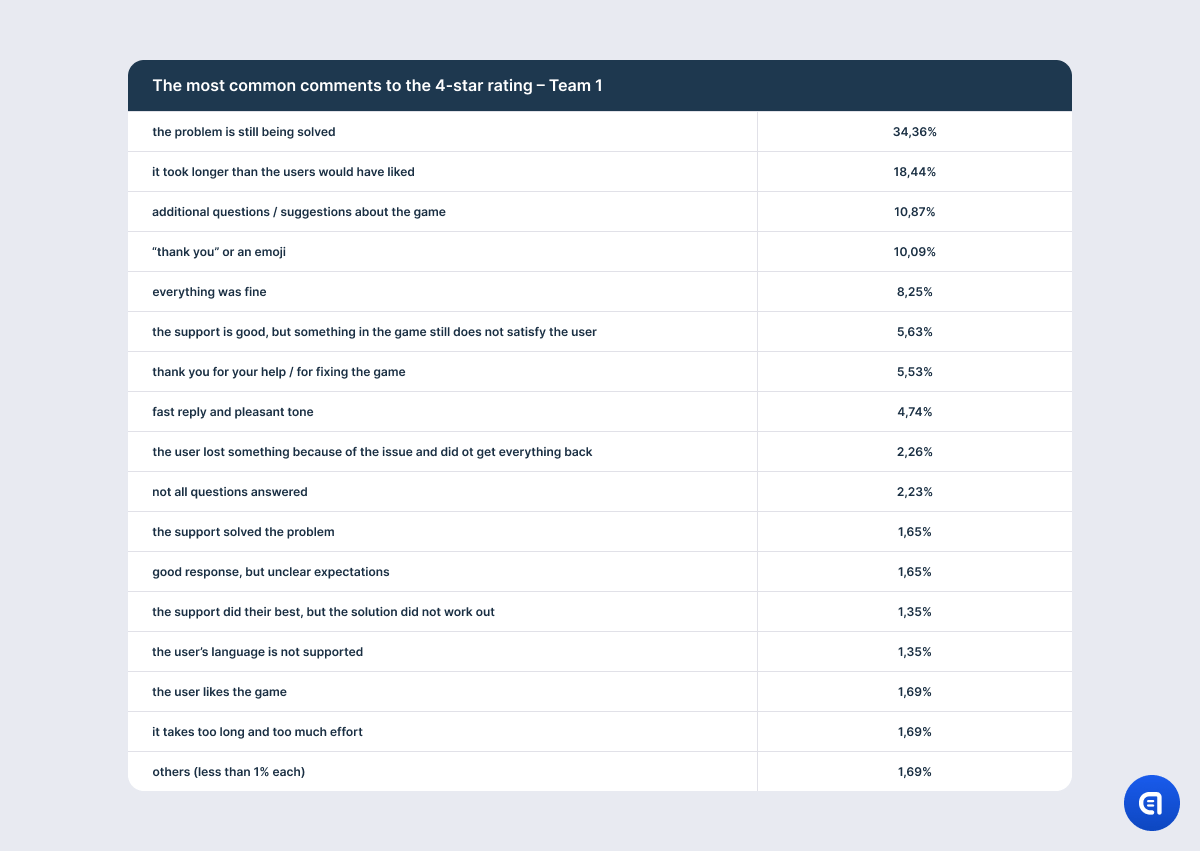
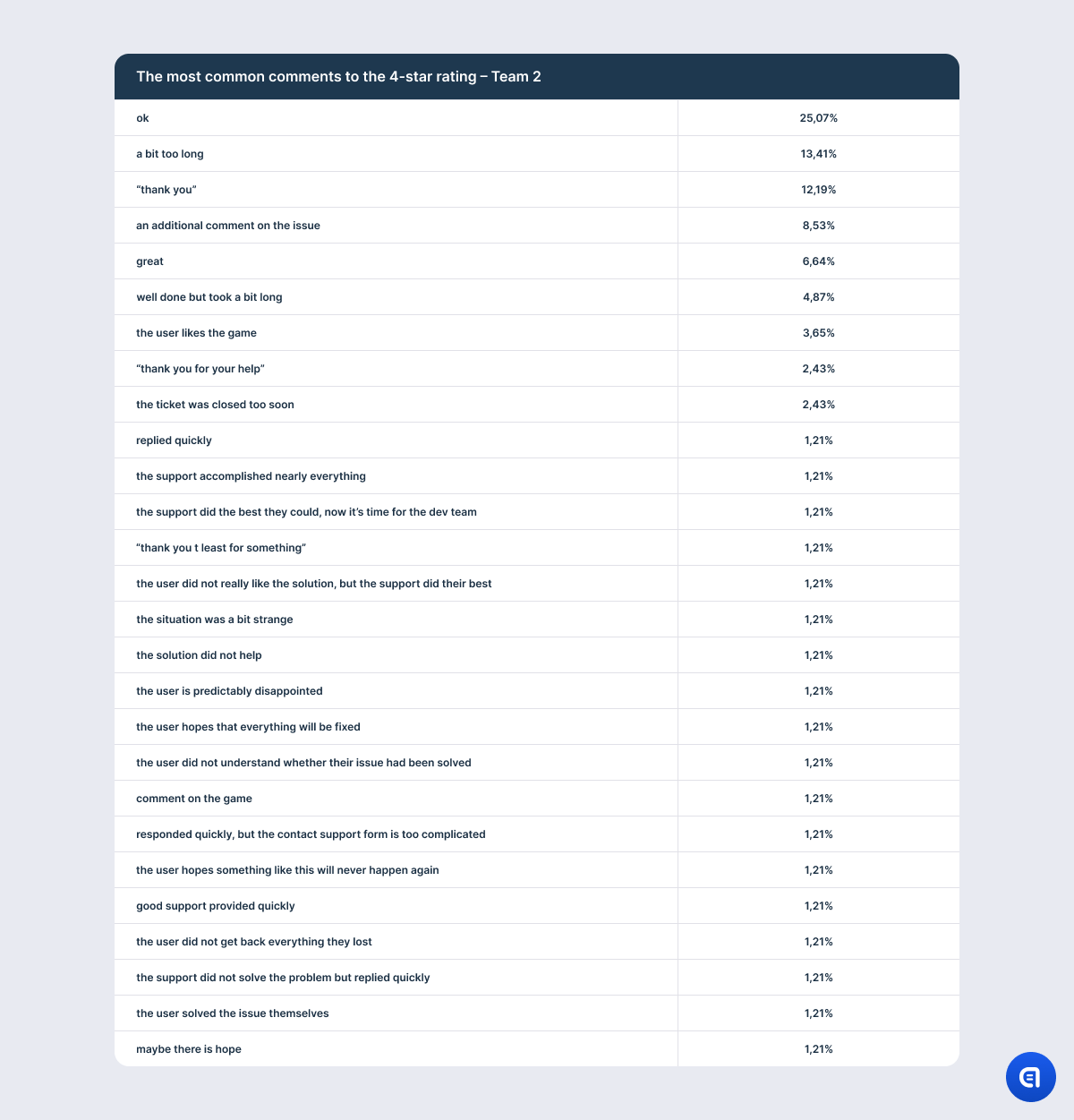
Negative feedback accumulates all the aspects that the user is not happy about. And it is evident that all of them influence the rating. For example, the user notes how friendly and polite the support is, but at the same time, they are unhappy that the game does not contain the necessary feature. As a result, they give the conversation only 3 stars.
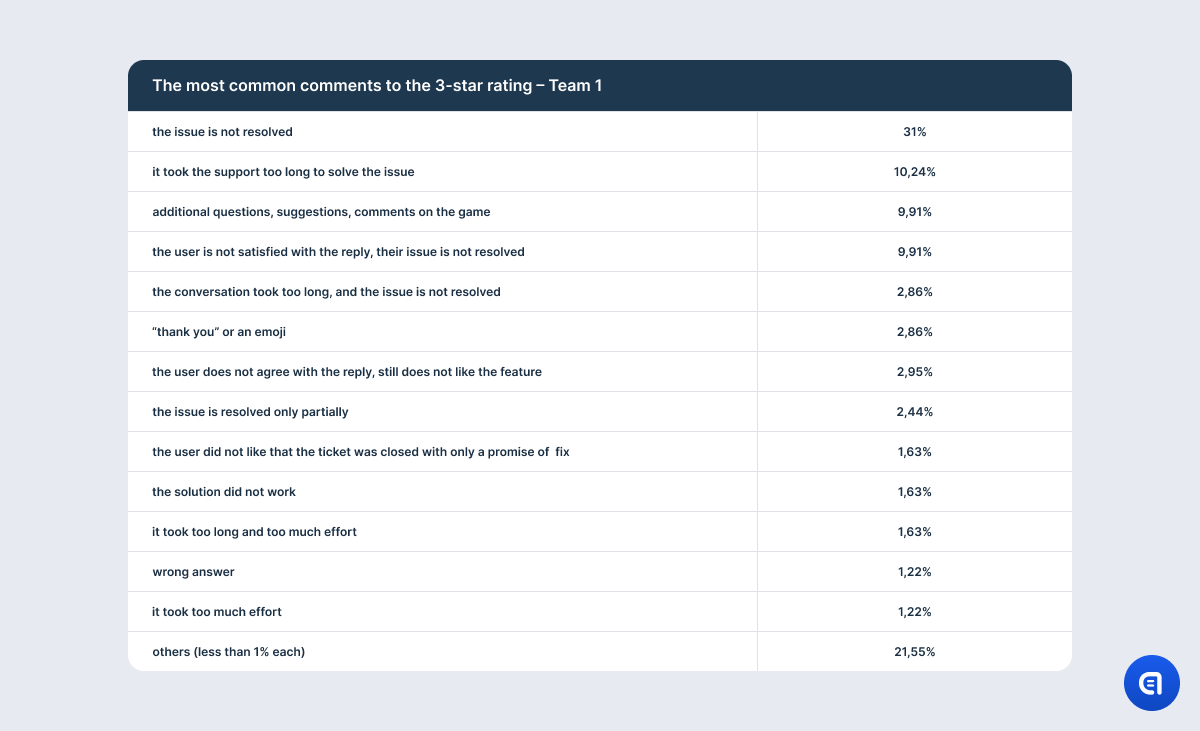
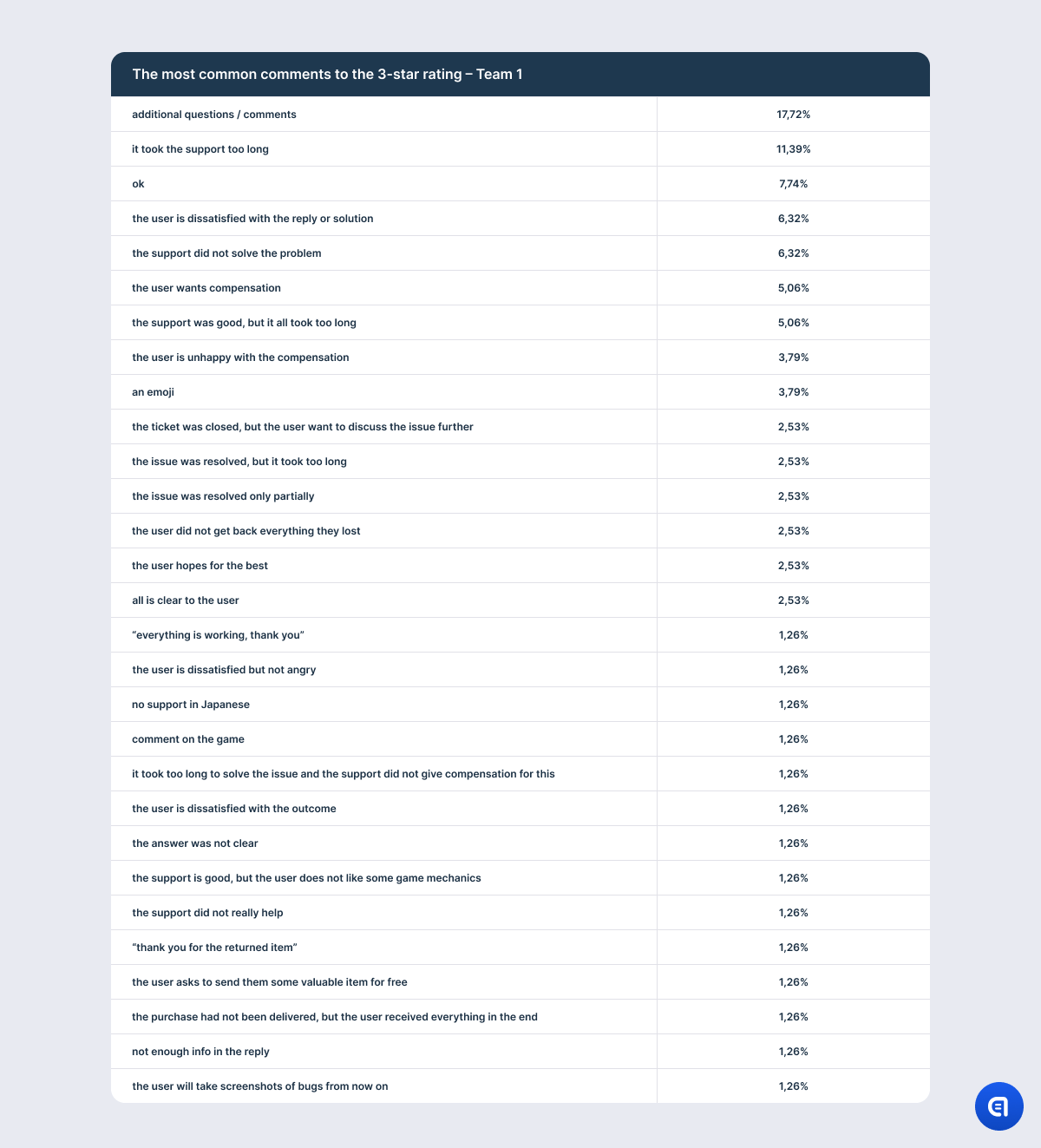
And it is absolutely natural since the user has only one way of sharing their emotions and describing what they dislike about the game. If the user were offered to evaluate different parameters (for example, the chat with support and game features) separately, we would have a different result and a more objective rating. When the user has only one opportunity to rate their experience, they will describe it all in one go. And we can fully understand the user’s intent only if they do leave a comment. Because if not, this negative feedback can be “put on the support’s tab”, while the user was actually displeased with the color of the event houses in the recent update.
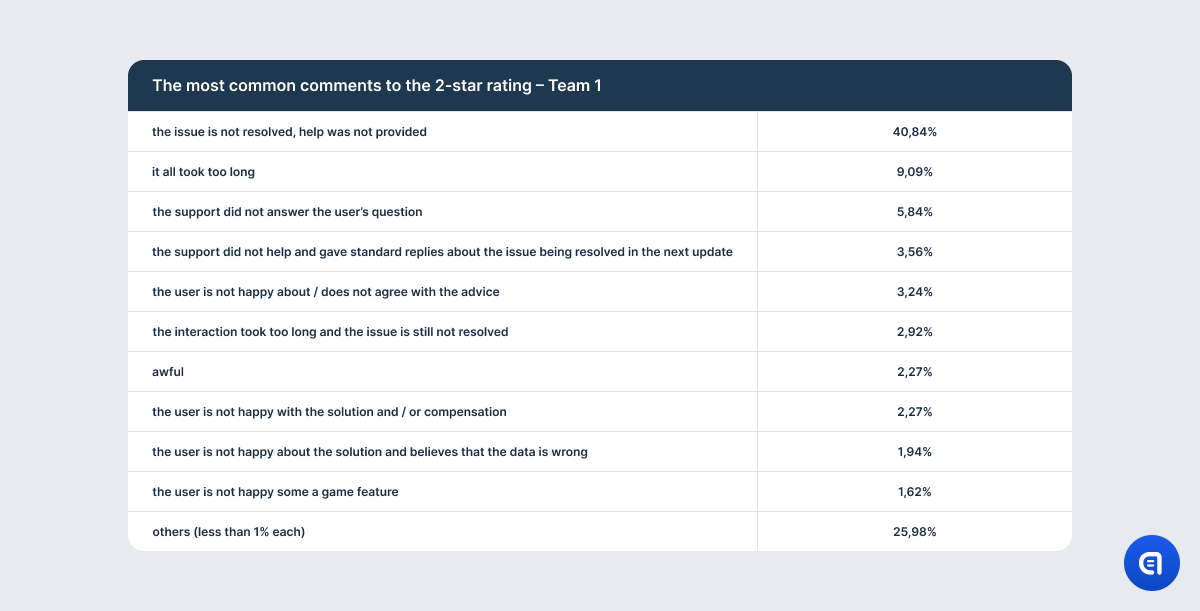
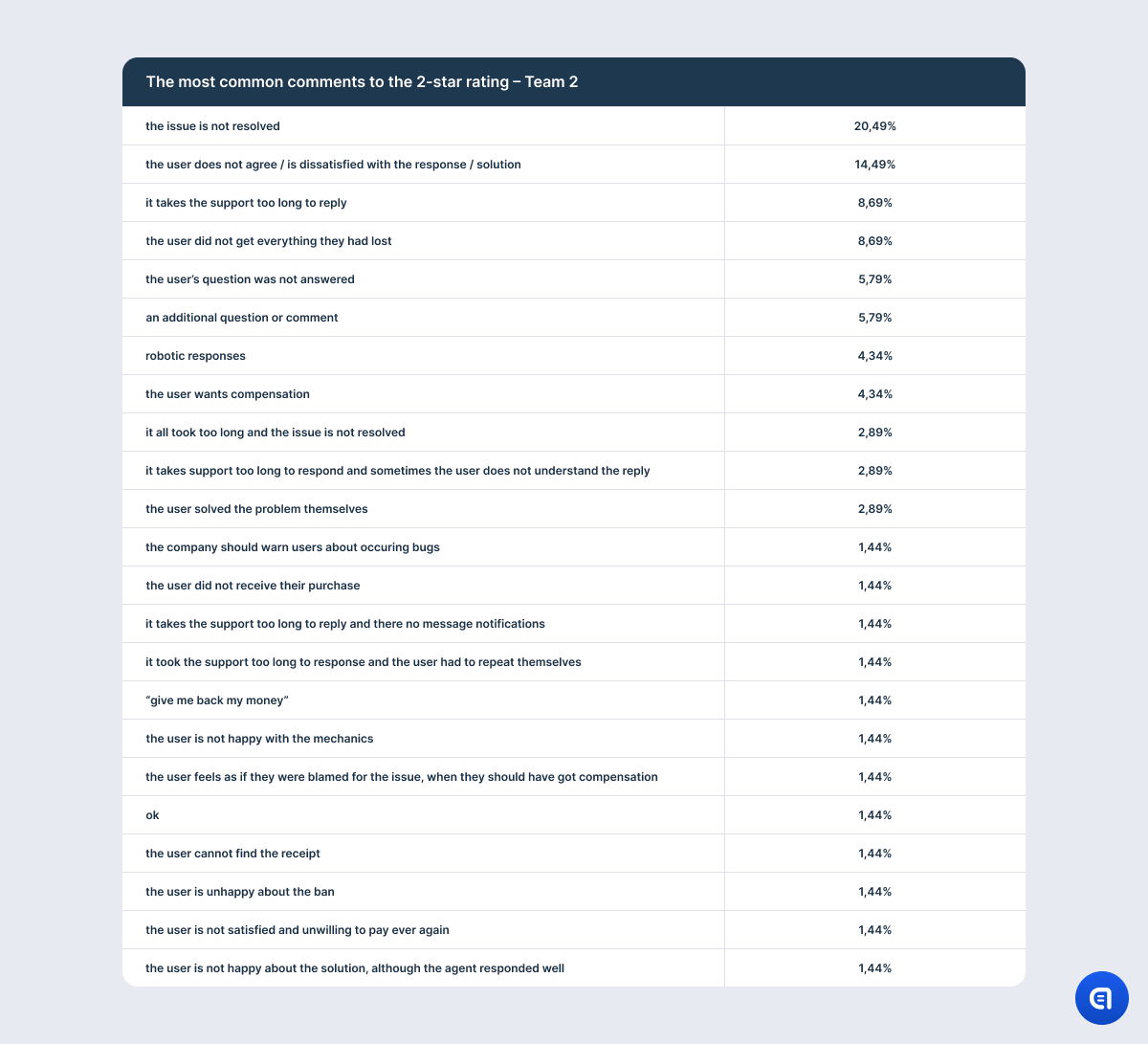
There are also aspects that, at first glance, have to do only with support quality. In fact, they are a part of a larger section of user experience, and they do not describe just one interaction with the brand like CSAT is supposed to. In other words, the user evaluates the whole mechanism of problem-solving, in which the support team is just a piece of the puzzle. And often, the support department cannot influence other elements of this mechanism or influence them indirectly. Users, naturally, do not care about the inner workings of the company; all they need is the result. But we are talking now about evaluating the quality of the support team as one of the parts of customer service, and it looks like CSAT may not fit this purpose.
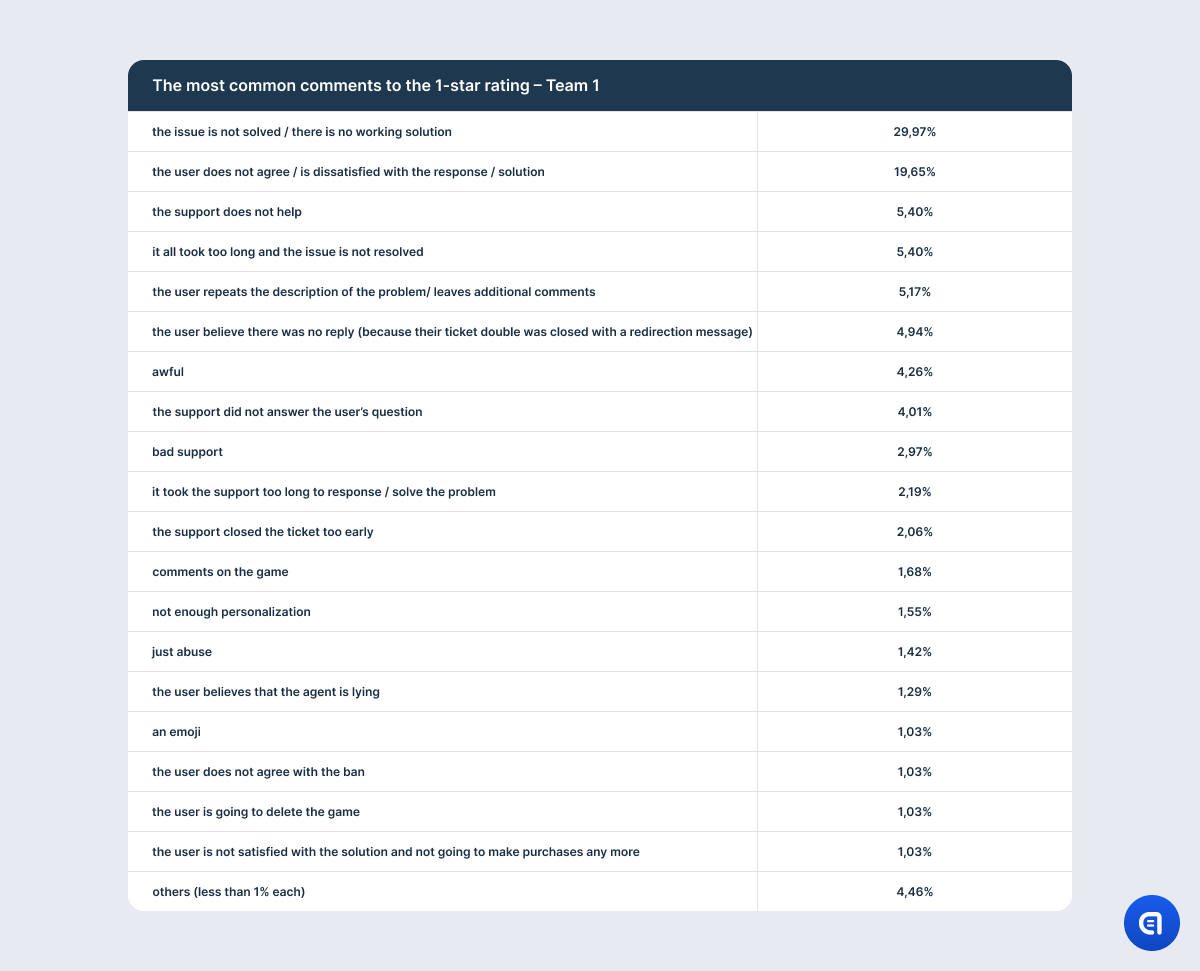
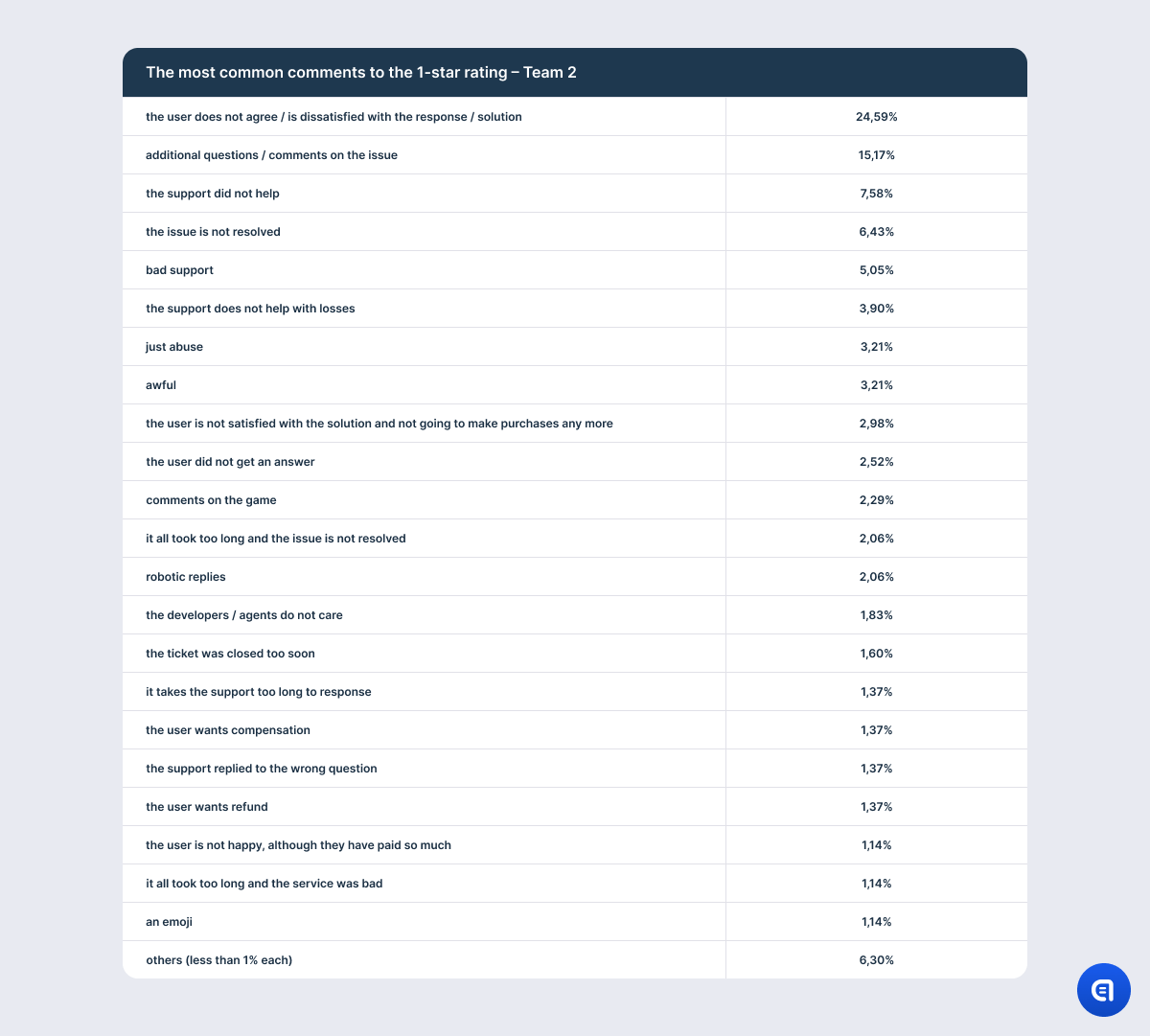
For example, the table with the results on the 1-star rating shows that the most irritating aspect for the users is that their issue is not resolved. However, this needs clarification. It is not that the support agent did not understand the issue or that they lacked the competence to solve the problem. The point is that there is a mass issue in the game, and in order to fix it, developers need time. So support often has to explain that the company has not forgotten about the users and that the dev team spares no effort to find a solution; however, it is physically impossible to fix the game at this very moment. It does not matter how good the agent is or how much empathy they put into their response. They may even offer an effective temporary alternative solution. However, if the problem has caused the user significant discomfort, anger, or frustration, the mere promise to fix the issue in the future will not calm them down. So at the end of the dialogue, the agent may still receive one star.
Here is another example: a game purchase cannot be refunded according to the company policy. In this situation, even Clark Gable’s charm will not save the agent – the user’s verdict will be “terrible support” and “the issue is not resolved”.
Or perhaps the game creators are particularly hard on cheaters, and some of them may receive a permanent ban. This situation does not even require an explanation. Banned users are capable of breathtaking word craftsmanship. If you want to enlarge your vocabulary, simply introduce permanent bans into your project.
Or maybe users complain that it takes support too long to solve their problem. Of course, first response time plays an important role here. However, the solution time depends not only on the ticket queue but also on the internal support processes. For example, some requests pass not only through the developers but also the legal department. Naturally, users know nothing about these obstacles. It is extremely important for the company to understand where their processes go wrong to correct them, but as far as users are concerned, the whole blame lies on the support department.
Level 4 – three in one but not coffee
The complaint about a long wait time can also be analyzed from a different angle. Let us compare, for example, dissatisfaction with the tone of the reply and dissatisfaction with the response time. In the first instance, the user is talking about emotional discomfort; however, waiting for a reply (be it a passive process) belongs to the area of user effort.
User effort has historically been the territory of CES metric; however, since the same principle of “I have this one opportunity to rate my experience, so I will include everything” works here, the criteria that “belong” to CES end up in the CSAT pool.
If we look closer at our feedback categories, we will find that, while measuring CSAT, we actually measure all three key metrics. For example, in the first team’s results, 30% of comments belong to CES; in the second team’s results – 19%. When a user complains about a long wait or solution time or about having to repeat themselves twice and send too many screenshots, it means that they spend too much effort on solving their problems. In this case, low CSAT also means high CES.
If the user writes that they will not play the game anymore and is going to write a crashing review in a store where they will strongly recommend that other players leave the game as well, you get an indirect NPS from an active and angry detractor.
It may seem that it is not that important what category a complaint belongs to. However, if you understand where it grows from, it will be easier for you to find a solution.
Without a detailed analysis, CSAT and user feedback resembles a salad where some ingredients are spoiling the taste. While they are all in one bowl, it is quite difficult to determine which ingredients you need to substitute. However, when we take them out, sort them, and taste each of them, we will know which ingredient is not right and how we can fix the recipe without having to rely on a try-and-error approach.
For example, if you receive a lot of complaints that fall into the CES category, you understand that you need to make your interaction with users easier and more comfortable. And if users are not happy with the response time or the amount of information you request from them, there is no use in escalating empathy and politeness; the issue lies within internal processes.
This is why in Ansvery we always maintain contact with our clients.
- We constantly analyze the support ecosystem.
- We build together and test information channels, and the effectiveness of communication between our agents and the client’s representatives.
- We collect and sort through user feedback, and our Quality Assurance team checks which communication techniques bring the best results.
Such collaboration allows us to spot emerging problems quickly and create a shared action plan. For example, reducing user effort has recently become a priority in our work with one of our clients. Shortening response time, setting up effective automation, maintaining up-to-date databases – all this can shift user opinion about the service for the better.
Read more: Triple Impact: How Support Affects Profit, Loyalty, and Customer Experience
Takeway
All in all, the traditional understanding of CSAT as rating a single interaction with the company does not seem to be true – if CSAT is the only metric that you use. The user often evaluates their whole experience with the company and products, including interface, app features, pricing, and communication. The user has only one opportunity to share their concerns, and so they will tell you about all their difficulties and their loyalty to the brand. It can be tricky to assess the role of customer support using just CSAT, especially since their functions are often limited to passing on the decisions of the dev team.
When we are talking about those spheres where users are prone to dramatic emotional changes – like gamedev – the fault in the calculation becomes even bigger. To get a more realistic result, we need to separate the acute emotional reaction to the situation in the game from the reaction to the competence of the customer service.
This does not mean that we should stop using CSAT, though. Depriving users of the only private way to share their opinion about the company can be quite damaging. Without this opportunity to vent, the user may go public and leave a review in an app store.
You can add some other metrics into your user survey; for example, ask your users other questions that will allow them to evaluate different aspects of their experience separately. Or you can rethink your approach to CSAT: concentrate not on your average score but on user feedback that accompanies their ranking. View comments as a pool of ideas that can help improve your work processes and suggest to you in which direction you can take your project.
The analysis of customer feedback also helps streamline interaction between support and other departments.
However, to evaluate just the quality of your support without any additives, you need different instruments that measure metrics unique just for this section of user experience. We shall look at those in detail next time.


